
SCHOOL OF ELECTRONIC ENGINEERING AND COMPUTER SCIENCE
QUEEN MARY UNIVERSITY OF LONDON, UK
ECS784U/ECS784P - DATA ANALYTICS - 2017/18
League of Legends: A Study of Early Game Impact
Raluca Gaina and Charlotte Nordmoen
June 9, 2018
Abstract
This study analyses the early game (first 10 minutes) performance of players in
the multi-player online battle arena game “League of Legends”. We characterise
performance through 4 features: experience earned, gold, damage taken and creep
score (the number of minions and monsters they kill). Using publicly available
data provided by Riot Games detailing 5v5 ranked games, we verify the impact
of the early game performance in the end game result of each individual player,
the overall team performance, as well as the match outcome. To this extent, we
analyse the correlation between player performance in the early and end game;
subsequently, we build a predictive model based on the early game features of each
of the 5 player roles identified to determine the game outcome. We find a medium
correlation between early game and end game performance of each player role,
but a weaker one when the early game and the overall team results are compared.
Our predictive model achieves 62% accuracy and is therefore comparable with the
state of the art. Applications of our system can be extended to player feedback and
skill improvement, as well as possible game adjustments for best player experience
from the beginning of the game.
1
1 Introduction
With the rise in popularity of online competitive games and esports, there is also a need
to better understand the game and performance of the players. As a result, researchers
have started developing data analytics and visualisation tools to generate statistics and
highlight interesting facts for a more in-depth look into gameplay [1]. A recent suc-
cess was “Echo”, a tool for visual analysis in the online multiplayer game “DotA 2” [2],
launched at ESL One Hamburg. “Echo” works live during gameplay to gather statistics
and overlay the information on top of the game in order to enhance the viewing expe-
rience for the public. A similar tool was developed for StarCraft II: “Scelight” offers
players diagrams and statistical information about the game, such as actions performed
every minute, game length, speed and other player specific information [3].
“League of Legends” is in many ways similar to “DotA 2”: a highly multiplayer
online game, but with a larger player base (67 million players playing the game every
month) and numerous professional match events during the year. The game complexity
is also increased, featuring 134 characters to choose from, each with different abilities,
strengths and weakness, over 400 rune tree path options and over 250 items to cus-
tomise each character in-game. In addition to the objective complexity, each player’s
decisions during one game can lead to a completely different outcome: all players
have different play styles and behaviours. Therefore, the game is highly noisy and
any statistics extracted need to take this into account and find a way to deal with the
large variety present in the data. However, the complexity and diversity also makes it a
highly interesting problem to analyse.
Several previous studies exist on the topic of win prediction in multiplayer online
games. Yang et al. look at combat patterns in order to predict the outcome of a match
in “DotA 2” [4]. Hodge et al. show that mixed-rank (including players of various skill
levels, or ranks) data sets analysis can successfully be used in predicting the results of
“DotA 2” professional competitive games; although there is a drop in accuracy, this
presents the potential of obtaining more data and still achieve positive results [5]. To
this extent, we use mixed-rank data sets in our study.
Kim et al. carry out an interesting team performance analysis in “League of Leg-
ends” using the concept of collective intelligence (CI) [6]. They base their hypothesis
on the idea that better cooperating teams have a higher chance of winning the game
regardless of their individual skills. Their results show that indeed CI during the later
phases of the game when the players are not separated, but expected to work more
together, leads to higher win rates, as well as being correlated with the social percep-
tiveness of the individual team members.
In contrast with this study, we focus on the early game phase (the first 10 minutes
of the game) and hypothesise that individual player performance in the early game has
an impact on their own overall performance, as well as the team’s outcome at the end
of the game. The performance is not only measured by the winning/losing state of
the game (which can only be determined at the end), but also the experience and gold
gained, the number of creeps killed and the damage taken from all various sources.
This hypothesis is motivated by the lack of research into the first stages of the
game, which many players consider critical: although comebacks are possible and the
middle or late game stages might provide more accurate information, the possibility of
2
clearly identifying issues as early as possible and having enough time to correct them
for better results would be highly useful to players at all levels of skill. Win predictors
in “DotA 2” can achieve up to 93% accuracy as opposed to the previously obtained
58.69% accuracy [7], but this only happens at minute 40 when it is highly unlikely the
players are able to modify their strategy in order to change the decided outcome.
2 League of Legends Background
“League of Legends” [8] is a multiplayer online battle arena game (MOBA) in which
two teams of either 3 or 5 players face off. In the rest of this report we will be focusing
on 5-player team games only, as the mechanics and strategies are different based on the
size of the team and the data we use is extracted from 5-player team games.
Each player chooses a character to play (champion) out of the 134 currently avail-
able, each having 4 different abilities. The players may further customize their champi-
ons in game by spending gold to purchase items (up to 6 inventory slots per champion,
with an extra 7th for vision items). All items have an effect on the various character
statistics: movement speed, attack speed, attack range, physical damage, magical dam-
age, armour, magical resistance, critical strike chance and health, with few exceptions.
There are several items which increase the gold earned in certain situations, as well
as vision items which can be placed on the ground in order to remove the Fog of War
from that area (for the team owning the vision item only); different types of vision
items exist which we will not go into detail about, as this is an area for future work
only and is not further discussed in the current project. Each champion also increases
their statistics when they level up (by gaining enough experience or XP).
The 5 versus 5 games are played on a square-shaped map called “Summoner’s
Rift”. Each team owns a base on either the top-right corner (“red” team) or bottom-left
corner (“blue” team), which consists of a large laser turret where each team spawns,
right in the corner, a nexus (when destroyed, the owning team loses the game), 2 turrets
protecting the nexus and 3 inhibitors towards the top, bottom and middle of the map
(which do not attack opponents and respawn when destroyed after 5 minutes). From
each inhibitor a path is drawn to the corresponding one on the other side of the map,
creating 3 lanes (named “top”, “middle” or “mid” and “bottom” or “bot”). Each of the
lanes are dotted with further 3 turrets for each team, protecting the inhibitors. These
have to be destroyed in order from the furthest away (otherwise they are immune to
damage). Between the lanes there is a “jungle”, which is covered in Fog of War (players
cannot see what is there unless another player on their team is in the area) and houses
several neutral monsters (they only attack if they get attacked first), as well as the 2 epic
monster camps (Rift Herald / Baron after 30 minutes in-game time; and Dragon). Epic
monsters have increased health and deal high damage, needing high leveled champions
and a group of them to take them down. Figure 1 shows a visualization of this.
Each nexus spawns waves of minions on each of the 3 lanes every 30 seconds,
which attack enemy champions, enemy minions and enemy structures. When they are
killed, they award the killing player gold, as well as experience to them and champions
nearby, in a small range. There are 4 different types of minions: Melee - has short
attack range, medium health; gives 21 gold and 59 experience. Caster - has long
3

Figure 1: Summoner’s Rift Map overview.
attack range, lower health; gives 14 gold and 29 experience. Siege - has long attack
range and high health; gives 60 − 87 gold (based on in-game time) and 92 experience.
Super - spawns only if the enemy inhibitor on that lane is currently down; has highest
health, low attack range and high damage; gives 60 − 87 gold and 97 experience.
It is worth noting that certain items give champions gold when those close to them
kill minions as well.
Based on these mechanics, 5 different player roles emerged which are most often
used in professional and ranked games (ranked games give the winning team points and
subtract them from the losing team, allowing players to fight for most points and better
ranks; we will be using the ranked queue type in this study, based on the assumption
that players give their best in these games):
• Top laner - starts the game in the top lane, furthest away from the early game
epic monster (the Dragon); most often a tank champion with more health and
resistance to damage.
• Mid laner - starts the game in the mid lane, close to all other team mates; most
often champions with magical abilities; they often move towards the other lanes
to help their teammates.
• Attack Damage Carry (AD Carry) - starts the game in the bot lane, closest to
the early game epic monster; almost always a physical damage champion; often
they achieve the highest creep scores (CS, the count of how many minions or
monsters they killed); usually they have the highest damage towards the end of
the game and their team will try to protect them.
• Support - starts the game in the bot lane, to offer assistance to the AD Carry;
usually they do not kill minions, relying on abilities or items to gain gold pas-
4
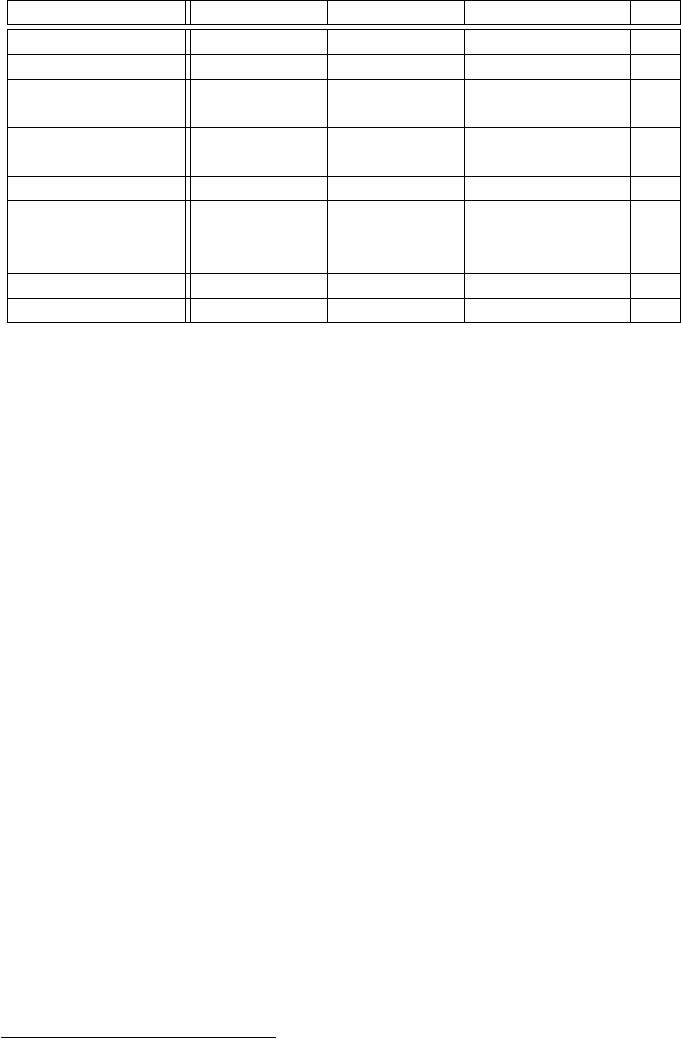
Gold XP Damage Taken CS
Enemy champion Kill / Assist Kill / Assist Source -
Enemy turrets Kill / In range - Source -
Enemy structures
(other)
Kill / In range - - -
Enemy minion,
neutral monster
Kill Kill / In range Source +1
Epic monster Team kill In range Source +1
Special items Own Own Source, if item
owned or used by
enemy champion
-
Vision items Kill - - -
Over time + gold - - -
Table 1: Ways of earning gold, gaining experience (XP), increasing creep score (CS)
and the sources of damage.
sively; they are responsible for keeping their teammates safe and offering utility
(e.g. vision) rather than damage.
• Jungler - starts the game in the jungle between the lanes, killing the neutral mon-
sters for gold and experience; they help the other players in the lane whenever
possible, launching surprise attacks on the enemies in the same lane.
See Table 1 for a recap of the various ways players may increase the values of the
4 features we are concerned with in this study: gold, XP, damage taken and CS.
.
3 Data set and pre-processing
The data set used in this project consists of gameplay data recorded from League of
Legends games, gathered from official resources released by Riot Games
1
. The data
is free to download by anyone from their website, after a quick registration process to
obtain an API key. To our knowledge, all registered users have access to the database
without the need for registration approval.
The data contains 1000 games, split in 10 different JSON files
2
of 100 games each.
All of the games are reportedly from season 9, game version 7.17.200.3955, as per
the meta information available for each game recorded. All games are played in a
particular queue, specifically Ranked Solo 5v5, which take place on the “Summoner’s
Rift” map. All code used in this project can be found on GitHub
3
.
The pre-processing step involved converting the large amount of data from the
JSON file formats into summarised data of interest in CSV file formats. This was
1
https://developer.riotgames.com/getting-started.html
2
https://s3-us-west-1.amazonaws.com/riot-developer-portal/seed-data/matches[1-10].json
3
https://github.com/rdgain/ExperimentData/tree/LoL-QMUL-EarlyGame-18
5
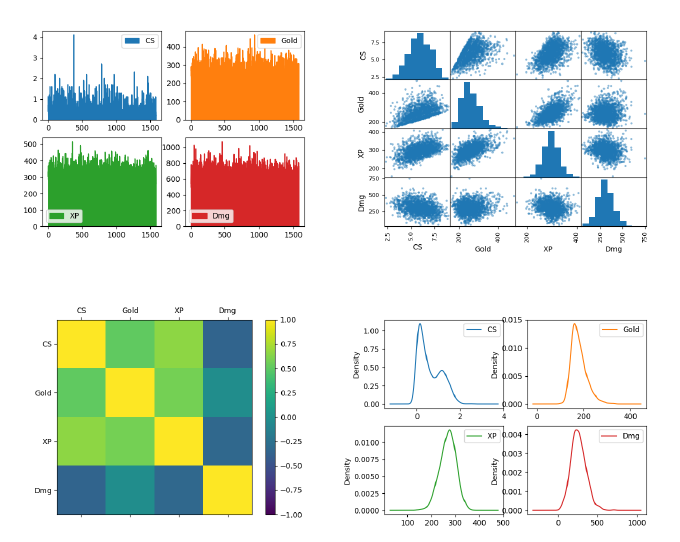
(a) “Jungle” role feature count. (b) “Cary” role feature relationship scatter.
(c) “Mid” role feature correlation heat map. (d) “Support” role feature density.
Figure 2: Visualisation of individual player role features.
done with python scripts (config.py and compute.py). Additionally, all data was com-
bined for easy access. The CSV formatted data was then explored further using the
pandas library for python.
Lastly, the data was reduced to only game where exactly 2 players for each role
are recorded in order to make sure the approximation and assumptions we make are
as accurate as possible. Moreover, ambiguous games which define the “Bottom” lane
roles as “DUO” without a clear specification are removed as well. Therefore, only 793
games are kept in the final data used for the project (so an equivalent of 1586 instances
for each player role).
3.1 Data exploration
The overall data was explored thoroughly in order to assess the information available.
As a result of this, several interesting aspects were observed.
Firstly, it turned out that the recorded gameplay data was sourced from 6 different
regions: Brazil (1 game), North America (988 games), Europe West (2 games), Europe
North-East (5 games), Turkey (1 game) and Latin America North (3 games). This
left two options, to strip the data and focus on only one region, or ignore the possible
6
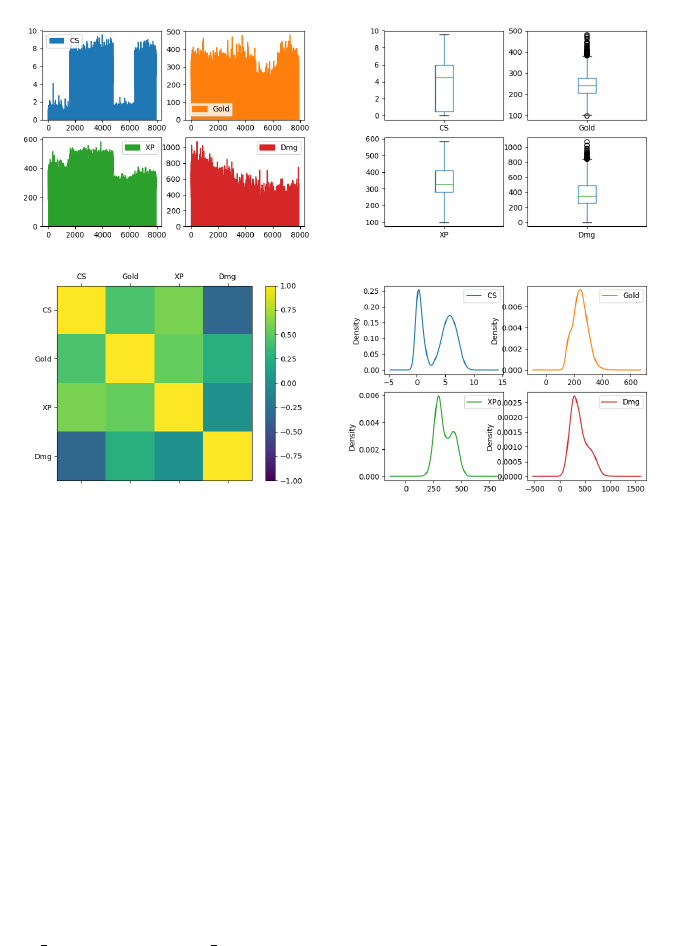
Figure 3: Features of all players, including feature correlation heat map.
noise multiple regions introduce in favour of a larger data set. The second option was
decided on, as our proposed study should be able to generalise across regions and does
not depend on any possible cultural differences. Therefore, all 1000 games are used in
this study.
Another aspect explored was the information available on which roles each player
took in the games recorded. Traditionally, the roles available, as described in Section 2,
are “Jungle”, “Top”, “Middle”, “Support” and “AD Carry”. When searching for these
specific roles, there are 2019, 1989, 2015, 1814 and 1814 reported players for each
role, respectively. The number of players each role should have is 2000, as there are 2
of each role in each game.
Therefore, the data was searched for all particular roles reported. The lanes re-
ported, which collate the “Bottom Support” and “Bottom Carry” roles are as follows:
{“Bottom”: 3977, “Jungle”: 2019, “Middle”: 2015, “Top”: 1989}. Additionally, the
specific roles of each player are reported as follows: {“Solo”: 3907, “None”: 2037,
“Duo Carry”: 1838, “Duo Support”: 1838, “Duo”: 380}. The ambiguity in the data
leads to the conclusion that the roles and lanes recorded are what the players requested
when they joined the game, not what they actually ended up playing.
To continue our study, we make the following assumption: in most cases, the
League of Legends matching system used the roles specified by the players as-is, giv-
ing those priority, therefore most players did play as the role recorded in the data. In
the cases where the players received a different role, it is assumed that the role they
7
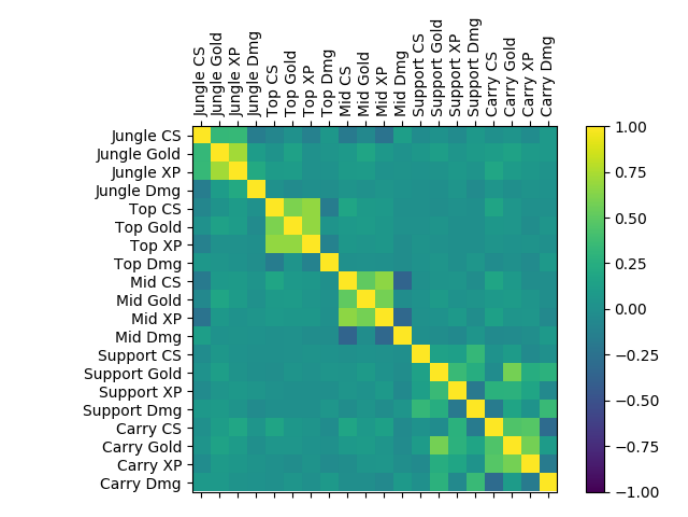
Figure 4: Visualisation of all feature correlations separated per player role.
specified is their speciality and their play style will remain similar even in different
roles. As described in Section 3, the data was however reduced to most relevant games,
in order for this assumption to not be too far-fetched.
For each role, the features identified as matching in the 0-10 minute time frame
to the end of the game statistics, as described in Section 4, were plotted in order to
observe the data in a visual way. Figure 2 shows four different ways of visualising
data (all features) for different roles: area plots for the “Jungle” role show the varia-
tion in the total 1586 players, the most being observed in the CS and gold features;
next, the relationship between the various features for the “Carry” role are described
through scatter plots, showing an interesting positive correlation between the gold and
the experience obtained, as well as a negative correlation between the CS and damage
taken by these players, which could lead to the idea that players who kill more minions
are less involved in fights and, therefore, less likely to take damage; the inter-feature
correlation is plotted as heat map for the “Mid role”, highlighting a general negative
correlation of all features with the damage taken (strengthening the previous idea) -
the fact that this is less pronounced for the gold highlights the fact that fighting other
champions is one way of actually earning gold. Lastly, the feature density is plotted
for the “Support” role, showing normal distributions for all but the CS feature which
peaks twice, separating players into those that do not kill minions and those that do, to
the detriment of their lane partner.
8
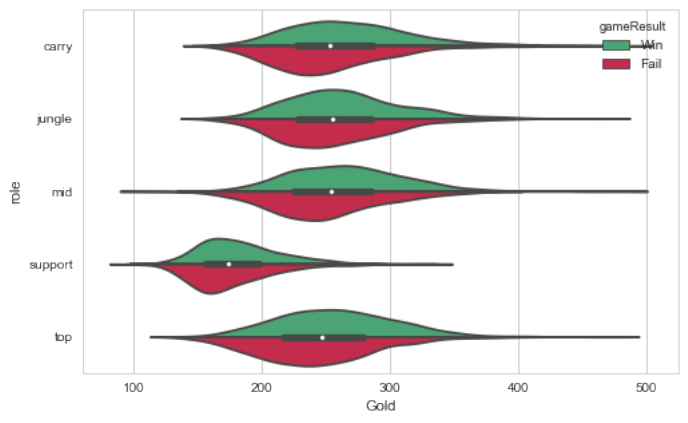
Figure 5: Players roles in relation to gold, separated in winning and losing teams.
Similarly, all features but without separating by player roles shows interesting pat-
terns in data, see Figure 3. It is interesting to observe the box plots, showing a multitude
of outliers for the gold and damage taken features, suggesting that there is a great diver-
sity between the player roles regarding these two features in particular. Additionally,
the “Support” players are clearly highlighted in the CS density plot.
Lastly, all features and all player roles correlations were plotted for comparison in
a heat map in Figure 4. Here it is most interesting to observe the positive correlations
in the bottom right corner, which indicates the dependency of the “Carry” and “Sup-
port” roles: their performances appear to be closely related. Another very interesting
observation is the negative correlation of the “Jungle” CS feature with most “Mid” and
“Top” features - this shows that “Junglers” who are more focused on killing neutral
monsters in the jungle are less likely to help their teammates, and therefore have a
negative impact in their performance.
Further relationship between the different features were examined through violin
plots from the Seaborn library. The advantage of this plot is that it combines a boxplot
with a kernel density estimation procedure [9]. Figure 5 shows how the various roles
preformed within the first 10 minutes of the game. A slight trend can be observed
where the winning teams tend to have more gold in this early stage of the game than
the losing teams. Of all the features gold seems to be the one feature that visually gives
the strongest indication of a correlation between early game performance and winning.
This will need to be examined further in order to confirm whether there is in fact a
correlation.
9

4 Approach
Based on previous studies [7] and the detail in the data available, the features we se-
lected for our analysis are as follows:
• Creep score (CS): the number of minions and jungle monsters killed
• Gold: the amount of gold gathered, resultant from minions, jungle monsters or
champion kills
• Experience (XP): the amount of experience earned, resultant from proximity to
minions, jungle monsters or champion kills
• Damage taken: the amount of damage taken from any sources
Together, these features are able to describe the performance of individual players,
as well as that of a team. Therefore, we carry out experiments to analyse the correlation
between early game and final player performance, as well as the correlation between
early game and final team performance. Additionally, we train a model on our data
in order to predict the outcome of one match based on the performance of individual
player roles (“Top”, “Jungle”, “Mid”, “Support” and “Carry”) in the early game.
4.1 Win/Fail Classification
7 different classifiers within the python sklearn library [10] were used to classify the
games according to the early game features identified. (classification.py) Their results
were analysed and compared, in order to ascertain that the results obtained are accurate
enough and not due to overfitting of one classifier or its poor performance on this
data set. The classifiers selected are fairly common ones from the sklearn library, their
quality and performance ranging from very simple (and sometimes worse than random)
decisions to complex statistical analysis:
• K-Nearest Neighbors (n neighbour = 3)
• Decision Tree (max depth = 5)
• Random Forest (max depth = 5, 10 estimators, max features = 1)
• Multi-layer Perceptron (alpha = 1)
• AdaBoost-SAMME [11] (default)
• Gaussian Naive Bayes (default)
• Dummy (default), simple rule predictor
The target classes were either ’Win’ or ’Fail’. The data set available contains 50%
of games won and 50% games lost. Therefore, a predictor which would always return
’Fail’ or ’Win’ would obtain a 50% accuracy. This was split into training and test sets
with a 0.2 ratio.
10
During training, 10-fold cross-validation was used. In most cases, classifiers are
not able to achieve an accuracy above 55% in the validation phase (all classifiers are
under this value for the “Jungle” role). For the other roles, the AdaBoost, Naive Bayes,
Random Forest and Decision Tree classifiers are able to achieve validation accuracies
of between 55% and 60%. The best result is given by the Random Forest classifier on
the “Mid” role, of 59% (+/- 0.09) accuracy.
5 Results and Discussion
5.1 Early game - End game individual player correlation
In general, there is a small positive correlation between the early game performance
and the end game overall result of individual players. Figure 6 shows this correlation
for the “Mid” role, the CS feature. This is one of the most pronounced correlations,
at 0.499, p-value <<0.01 according to the Pearson statistical test. The overall high-
est correlation is actually 0.55 with p-value <<0.01 for the “Support” role in the CS
feature. The smallest correlation is found for the “Top” role in all features, smallest
in gold at 0.21. This suggests that the “Top” role is least dependent on the early game
regarding individual performance, whereas the “Mid” and “Support” early game has
the most impact in their individual final results.
No significant difference was observed where winning and losing teams are con-
cerned - this individual player correlation does not appear to be an indication for the
outcome of the game.
5.2 Early game - End game team correlation
Next we verified correlations between the early game performance of individual players
with that of the overall end game team performance. These are generally much lower
than previously observed, reaching a maximum of 0.21 for the “Mid” role in the CS
feature, see Figure 7. As the highest correlation are observed in the CS feature, Table 2
shows all Pearson r values for the different roles, as well as the corresponding p-value.
Most of the results are significant with p <5, with the exception of the “Jungle” role. It
is interesting to observe the high variability in “Junglers” performance, as well as the
low correlation seen in the “Carry” role, which is expected to simply increase their CS
in the early game as their main source of income for better items later on. This could be
explained by the “Carry” switching from killing minions to killing champions towards
the later stages in the game, thus reducing the correlation.
Finally, Table 3 looks at the end game individual player performance compared to
the overall team performance, for the same CS feature which shows highest correlation
values. These suggest that generally the “Top”, “Mid” and “Carry” roles obtain the
most CS during the game, whereas the “Support” role counts the least, all expected
results, but interesting insights.
11
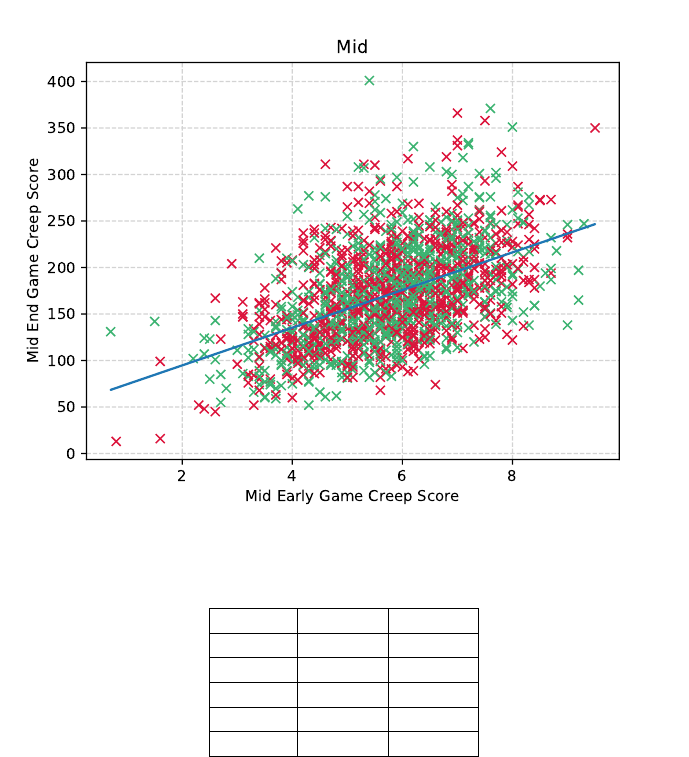
Figure 6: CS of early game “Mid” role correlation with end game CS of same role.
Wins (green) and losses (red) are highlighted.
Role Corr p-value
Jungle <<0.01 0.99
Top 0.17 <<0.01
Mid 0.21 <<0.01
Support 0.1 <<0.01
Carry 0.15 <<0.01
Table 2: Correlation between each role’s early game CS vs the team’s CS. Result is
significant if p-value < 0.05, according to Pearson statistical test.
5.3 Win/Fail classification
During testing, the results of all classifiers explored for the “Jungle role” are again
unsatisfactory, similar to the validation phase. The best results obtained are 62% for
Top (f1 score = 0.63, Random Forest classifier), 61% for Support (f1 score = 0.61,
Naive Bayes classifier) and 61% for Carry (f 1 score = 0.62, AdaBoost classifier).
Although the accuracy given by the classifiers is not very high, it is still significantly
better than random in most cases. As League of Legends is a highly varied game,
with many variables which can induce noise in all results, this can be considered a
satisfactory result, with the possibility of increasing the classifier’s accuracy with more
12
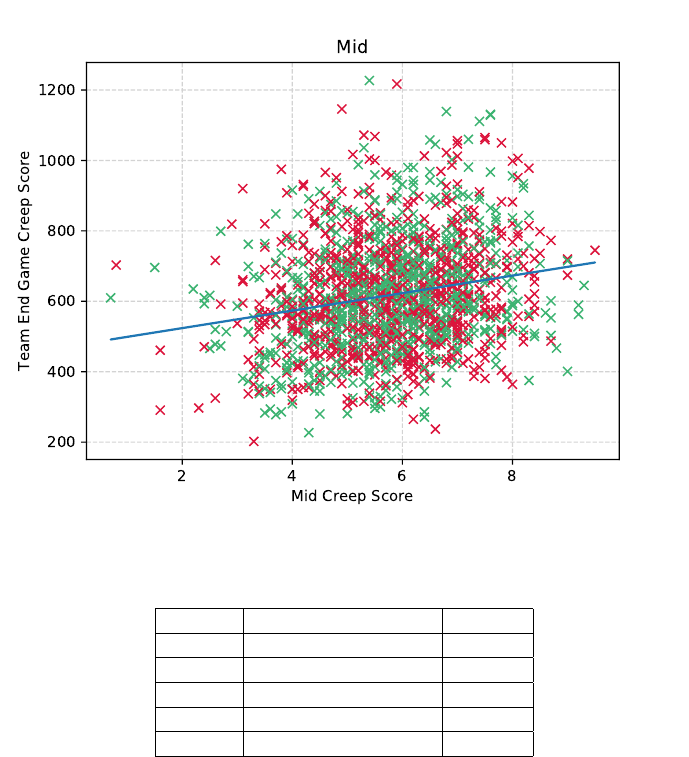
Figure 7: CS of early game “Mid” role correlation with team CS. Wins (green) and
losses (red) are highlighted.
Role Corr p-value
Jungle 0.5516730701595891 <<0.01
Top 0.7832963161382542 0.0
Mid 0.7556678847415031 <<0.01
Support 0.4415102617837788 <<0.01
Carry 0.8256292303798384 0.0
Table 3: Correlation between each role’s end game CS vs the team’s CS. Result is
significant if p-value < 0.05, according to Pearson statistical test.
data and more features extracted from gameplay.
Another conclusion that can be drawn from these results is that the early game
matters the most for 3 roles in particular: “Top”, “Support” and “Carry”. Therefore,
further studies can be two-fold. On one hand, a deeper analysis into these 3 roles can be
performed in order to identify further reasons as to why they rely more on early game
performance than the other ones. On the other hand, the “Jungle” and “Mid” roles can
be looked into to identify other details from the early game performance that do make
a difference (for example, the “Jungle” role’s pathing choices or the “Mid” control of
the lane; both of these features, however, would require positional data).
13
During training, the most important features per role (order is: [CS, Gold, XP,
Damage]), according to the sklearn implementation of a Decision Tree Classifier, were
identified as follows:
• Jungle: [0.0327 0.399 0.178 0.391] - Gold and Damage Taken
• Top: [0.137 0.282 0.411 0.169] - XP
• Mid: [0.122 0.558 0.154 0.169] - Gold
• Support: [0.057 0.289 0.349 0.304] - XP
• Carry: [0.025 0.474 0.287 0.214] - Gold
• Overall / all players: [0.033 0.373 0.178 0.416] - Damage Taken and Gold
• Overall / team: [0 0.018 0.053 0.025 0.038 0.025 0.130 0.021
0.067 0.248 0.017 0.099 0 0.058 0.032 0 0.010 0.130 0.027 0]
An expected result is that the “Support” role does not rely on the CS or Gold fea-
tures as much, as their main focus should be assisting the “Carry” in gaining his Gold.
It is interesting, however, to observe that the “Top” laner relies quite heavily on early
game experience gained, as well as benefiting from CS a lot more than most of the
other roles.
The fact that the “Jungle” role should minimize damage taken is another interesting
find, particularly as this and Gold earned are valued higher than the CS or experience
obtained. This could mean that successful “Junglers” focus more on staying healthy
while farming the jungle in the early stages and on helping their teammates, instead of
simply killing the jungle monsters for their own benefit.
When all players are included for an overall early game classification, the results
indicate that the Gold and the damage taken features are the most important. Of course,
CS does lead to a Gold increase naturally, but as there exist other sources of Gold, this
leads to the conclusion that CS is actually not the main source of income in the early
game, as it is often highlighted by experienced players.
If the entire team is evaluated (that is, all features for all players on one team in-
cluded as a data point), then it turns out that the most important features are the “Top”
laner’s experience and the Gold earned by the “Mid” laner and the “Carry”. Contrary
to a previous result, this shows that the “Mid” role is more significant to the team per-
formance than the “Support”, but also more reliant on the performance of the rest of
the team, whereas the “Support” appears to be more self-sufficient than the “Mid” role.
6 Conclusions and Future Work
This project was focused on studying the impact that the early game performance of
individual players has on the outcome of a match in the multiplayer online battle arena
(MOBA) game “League of Legends”. We hypothesise that the early game does have a
high impact in the match outcome. To this extent, we analysed data from 5v5 ranked
games played on the “Summoner’s Rift” map, using four features as a measure of
14
performance: experience earned (or XP), gold, damage taken and creep score (or CS,
the number of minions and monsters killed).
We started by verifying the correlation between individual player early game and
end game performance and observed that the “Top” player is least likely to be impacted
by their early game performance, whereas the “Mid” and “Carry” roles see a larger
early game impact. This is most pronounced in the CS feature, followed by the damage
taken by the player. Next, we checked the correlation between individual early game
performance and end game overall team performance - there was an expected drop
in correlation, in particular for the “Jungle” role. The interesting negative correlation
between the “Jungle” role CS and most features of the “Top” and “Mid” roles suggest
that “Junglers” who spend more time killing jungle monsters are less likely to help
their teammates, leading to worse performance; however, we have also seen that the
“Support” and “Carry” roles require less early game assistance from their teammates,
while their performances being highly reliant on each other.
The impact observed from the early game performance on the end game individ-
ual, as well as overall team performances rejects the null hypothesis, although the low
correlation values do not confirm our hypothesis either.
Lastly, we built a predictive model based on the early game features identified for
each role, intending to predict the outcome of a game based on the performance of
each individual role. We used 7 different classifiers in order to try obtain the best
models possible, obtaining 61 − 62% accuracy for all player roles. By analysing the
feature importances determined by our Decision Tree Classifier, we discovered that the
“Jungle” role should aim to minimize damage taken early game, as well as the fact that
“Junglers” who focus more on helping their teammates instead of killing the jungle
monsters have a higher chance of winning the game. Additionally, the CS feature
does not have a high impact in the “Carry” and “Mid” roles even in the early game,
suggesting aggressive players to be more successful than passive ones. The results
also suggest that both the “Top” and “Support” roles should focus most on earning
experience and levelling up to be able to better support their teammates, instead of
their own CS or gold increase.
The relatively low accuracy is due to the game being very noisy and full of uncer-
tainty, as analysed by Ferrari in [12]. However, the reported results are very positive, as
only early game features are considered; in [7], Yang et al. method achieves 67% ac-
curacy in predicting DotA 2 outcomes at 10 minutes without prior features (using gold,
experience and deaths as performance indicators). Taking into account the increased
complexity in the problem studied in our work, our results are comparable with the
state of the art in the area of MOBA outcome prediction.
Regarding future work, we are planning on adding more features for a better model
of player performance, such as kills/death/assists in the first 10 minutes compared to the
overall results, positional and communication data (i.e. pings), as well as vision data.
Additionally, we will look into incorporating player historical data into the analysis,
which should provide a great boost in accuracy for our match outcome predictor.
These results could not only be used to allow players to improve their performance
during the game, by receiving information about what features are causing the predictor
to currently indicate a loss and allow them to correct the issues, but also to tweak the
game so as to provide the best player experience possible from the very beginning
15
of a match; using player data analysis in game development is a common practice
seen in the Procedural Content Generation area of research [13], but also adapted for
commercial games (such as “Battle Islands”, who use player data analysis to balance
the game and increase player retention).
References
[1] M. S. El-Nasr, A. Drachen, and A. Canossa, Eds., Game Analytics, Maximizing
the Value of Player Data. Springer, 2013.
[2] U. of York DC Labs and ESL, “Capturing the extraordinary: Echo brings es-
ports statistics to life,” in available online: https://tinyurl.com/ybo7xbe4, October
2017.
[3] A. Belicza, “Scelight,” in available online: ttps://sites.google.com/site/scelight.
[4] P. Yang, B. E. Harrison, and D. L. Roberts, “Identifying patterns in combat that
are predictive of success in MOBA games,” in FDG, 2014.
[5] V. Hodge, S. Devlin, N. Sephton, F. Block, A. Drachen, and P. Cowling, “Win
Prediction in Esports: Mixed-Rank Match Prediction in Multi-player Online Bat-
tle Arena Games,” arXiv preprint arXiv:1711.06498, 2017.
[6] Y. J. Kim, D. Engel, A. W. Woolley, J. Y.-T. Lin, N. McArthur, and T. W. Malone,
“What Makes a Strong Team?: Using Collective Intelligence to Predict Team
Performance in League of Legends,” in CSCW, 2017, pp. 2316–2329.
[7] Y. Yang, T. Qin, and Y.-H. Lei, “Real-time eSports Match Result Prediction,”
arXiv preprint arXiv:1701.03162, 2016.
[8] Riot Games, “League of legends,” Computer Game, 2009.
[9] Seaborn.pydata.org, “Plotting with categorical data — seaborn 0.8.1 documenta-
tion.” [Online]. Available: https://seaborn.pydata.org/tutorial/categorical.html
[10] L. Buitinck, G. Louppe, M. Blondel, F. Pedregosa, A. Mueller, O. Grisel, V. Nic-
ulae, P. Prettenhofer, A. Gramfort, J. Grobler, R. Layton, J. VanderPlas, A. Joly,
B. Holt, and G. Varoquaux, “API design for machine learning software: experi-
ences from the scikit-learn project,” in ECML PKDD Workshop: Languages for
Data Mining and Machine Learning, 2013, pp. 108–122.
[11] J. Zhu, S. Rosset, H. Zou, and T. Hastie, “Multi-class AdaBoost,” Ann Arbor, vol.
1001, no. 48109, p. 1612, 2006.
[12] S. Ferrari, “From Generative to Conventional Play: MOBA and League of Leg-
ends,” in DiGRA Conference, 2013.
[13] N. Shaker, G. N. Yannakakis, and J. Togelius, “Towards Automatic Personalized
Content Generation for Platform Games,” in AIIDE, 2010.
16
